Find gaps with guided practice

Table of Contents
📊ap statistics review
5.3 The Central Limit Theorem
Verified for the 2025 AP Statistics exam•Citation:
Definition
The Central Limit Theorem is often tested on free response questions dealing with quantitative data (means). Now, you cannot assume that the sample is normally distributed. The question must either explicitly state so, or you have to follow the central limit theorem.
The Central Limit Theorem states that if a sample size (n) is large enough, the sampling distribution of the sample mean will be approximately normal, regardless of the shape of the population distribution. In general, a sample size of n > 30 is considered to be large enough for the Central Limit Theorem to hold. 🔔
It's also important to note that for the Central Limit Theorem to apply, the samples must be independent of each other and the sample must be a simple random sample. Additionally, it is generally recommended to use the Central Limit Theorem only for continuous variables, as it may not hold for discrete variables with small sample sizes.
To summarize, for a quantitative sample to be normally distributed according to the Central Limit Theorem, it should meet the following criteria:
- The sample size (n) is large enough (usually n > 30).
- The samples are independent of each other.
- The sample is a simple random sample.
Example
Use the Central Limit Theorem when calculating the probability about a mean or average.
For example, if a question asks for the probability about the mean size of fish, you cannot assume that the sample of fish, say in a pond, is greater than 30 unless the problem states so.
In this question, reasoning might include that since the sample of fish is 40, which is greater than 30, it is approximately normal. This is because according to the central limit theorem, if n is large, then the sample is approximately normally distributed. Additionally, you must state that the samples are independent of each other. This is true for both quantitative and categorical data (and the statement is the same).
You must explicitly state that you assumed the sample is normally distributed because of the central limit theorem.
The picture below shows what happens as you increase your sample size. The smallest triangle is a sample size of 5 and the tallest is a sample size of 100. 🔺
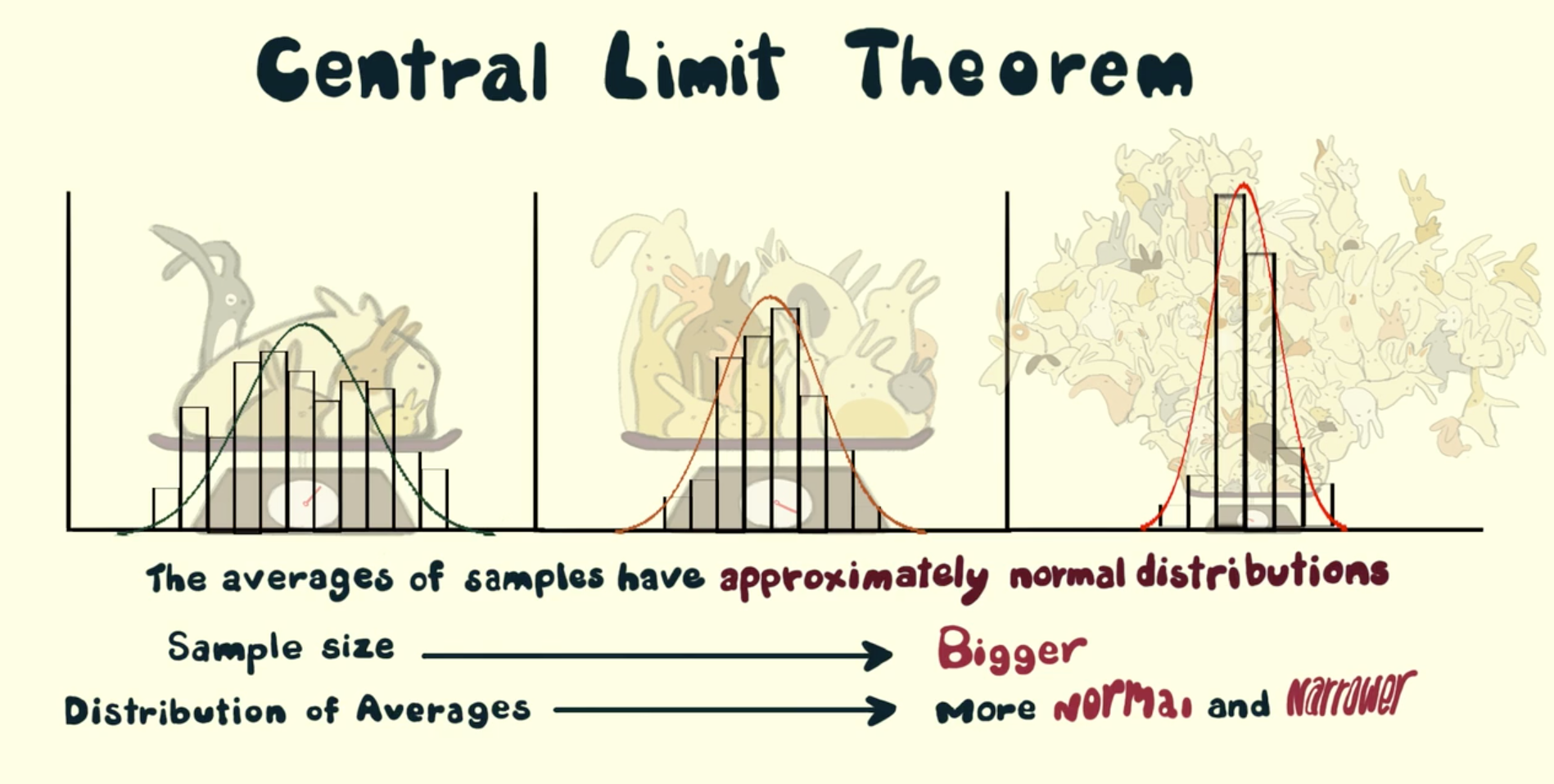
Bigger is Better!
With sampling distributions, the larger the sample size, the less spread the curve is going to have. This is because the larger a sample is, the more the sampling distribution is going to hone in on the true population parameter.
Think of this... if you flip a coin 6 times, the proportion of heads you get is likely to be greater than or less than 0.5 (the data is somewhat skewed). However, once you flip the coin 50, 100, 1000 times, it is very unlikely that the proportion of heads is going to be much different from the true population proportion, which we know is 0.5.
Due to this concept, the larger the sample size, the better. A large sample size allows us to hone in on the population parameter (either 𝝁 or 𝝆), which is EXACTLY what we are after when using a sampling distribution. 😄